
物体検出AIであるYOLOv7を使って、自分の撮った写真に何が写っているのか・・・というか自分は何をどれだけ撮っているのかを調べようと思った。もし比較的簡単にうまく学習できるなら、何をどのような構図で撮っているか、みたいな分析もできるかも。
テストケースとして、自前データで猫認識AIを作成しようと思う。
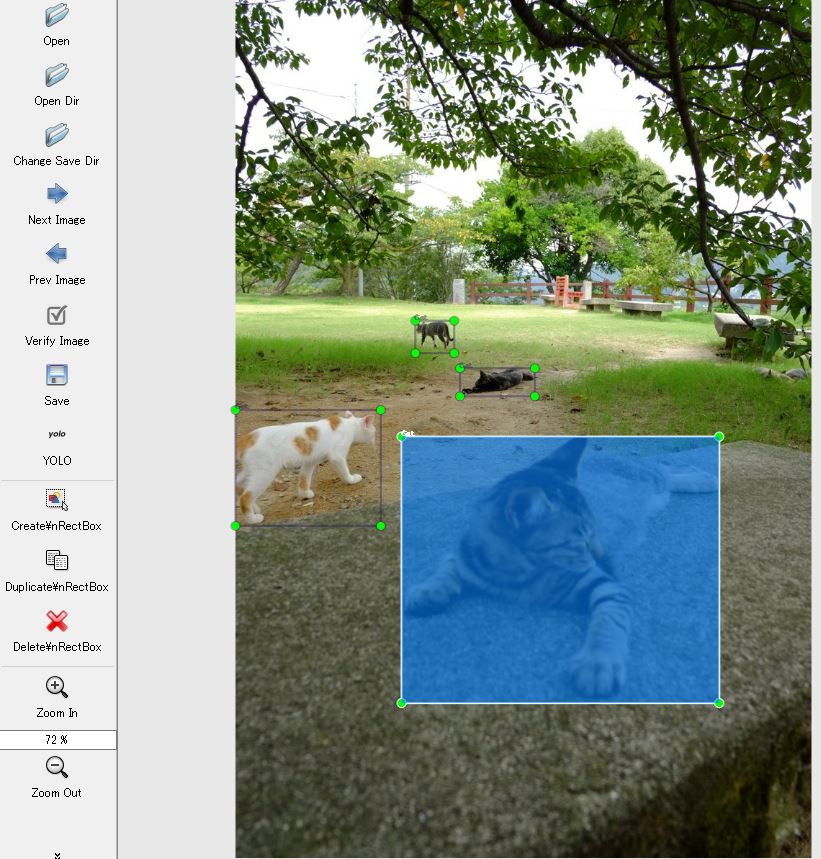
labelImgというツールを使って、300枚ほどの写真にラベルを付けた。疲れた。なお写真はすべて自分で撮った写真を使ったが、AI学習用のデータとしては著作権を気にする必要はないらしい。
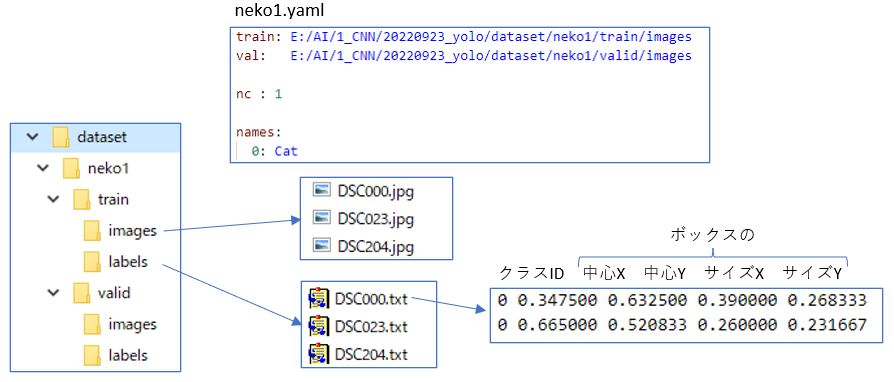
次に、このデータをtrainとvalid、さらにimagesとlabelsに分けてフォルダに保管。データセットを記述するyamlは、面倒なので絶対パスで書いた。
YOLOv7をgithubからクローンしてくる。
https://github.com/WongKinYiu/yolov7
ベースとなる重みyolov7x.ptもダウンロードしてくる。
https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7x.pt
バッチサイズはGPUメモリの許す限り大きく・・・って8GBメモリではバッチサイズ4が限界か。Google Colaboratoryでやった方がよさそうだが、今回はローカルで実行。
python train.py --workers 1 --img-size 640 --batch-size 4 --data ../dataset/neko1.yaml --cfg cfg/training/yolov7x.yaml --weights yolov7x.pt --name yolov7x --hyp data/hyp.scratch.p5.yaml --epochs 500 --device 0
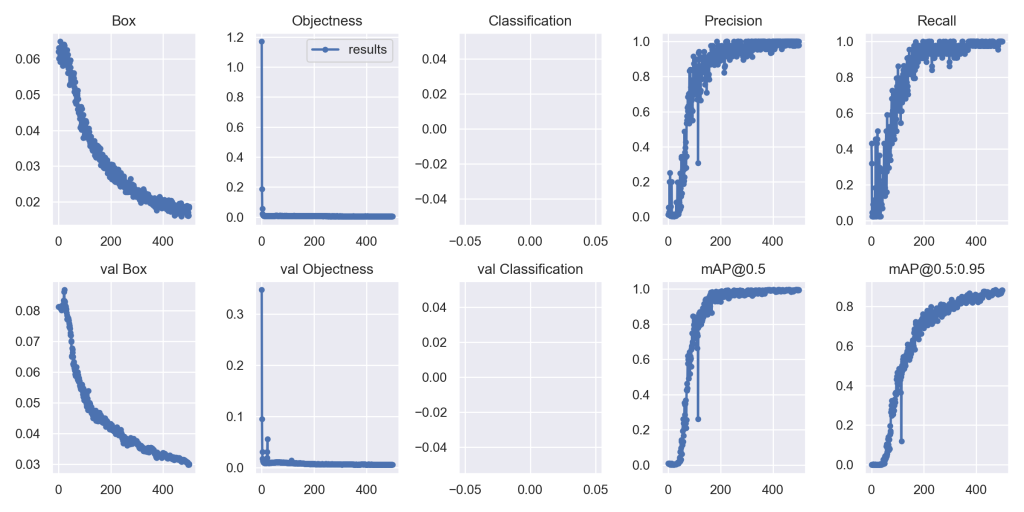
3時間くらい放置していたら、500エポック終わっていて、runs/train/yolov7xに学習結果が書き出されていた。もう一つ見方が分かっていないけど、Boxとval Boxを見るに、まだ減少中なので、もうちょっと続ければ精度の改善が期待できる・・・のかな?
とりあえず、runs/train/yolov7x/weights/best.ptを使って、推論を行ってみよう。
python detect.py --source inference/test_images/ --weights runs/train/yolov7x/weights/best.pt --conf 0.4 --img-size 640 --device 0 --save-txt --save-conf

まぁ悪くはないけど、1クラス(猫)のみという単純なケースで300件の学習データを用意して、学習に3時間もかけた割に・・・という印象。物体検出は全然経験がないんだけど、単なる画像認識よりは学習が難しいのかな。
このまま進めるかどうかはやる気次第・・・。
余談だが、最初labelImgではなく、labelmeでラベリングを始めたが、labelmeで書き出されるjsonをYOLOフォーマットのtxtに変換する必要があった。その後はlabelImgでは最初からtxtで出力できることを知って、そちらに移行したが、jsonからtxtに変換するコードを書いたのでメモしておく。ちょっと変えれば、Coco形式でも書き出せると思うが使わないので作らない。
import json
import glob
from PIL import Image
import os
"""
convert json created by labelme to yolo text format
"""
os.chdir(os.path.dirname(os.path.abspath(__file__)))
json_list = glob.glob("data/*.json")
# classes.txtがある場合
with open("classes.txt", "r") as f:
lines = f.readlines()
cat_id_dict = {} # Category Name to Category ID Dict
for i, line in enumerate(lines):
cat = line.replace("\n", "")
cat_id_dict[cat] = i
# classes.txtがない場合
# cat_id_dict = {
# "person" : 0,
# "cat" : 1,
# "dog" : 2
# }
for json_file in json_list:
print(json_file)
img_path = os.path.splitext(json_file)[0] + ".jpg"
txt_path = os.path.splitext(json_file)[0] + ".txt"
with open(json_file) as f_in:
json_data = json.load(f_in)
img = Image.open(img_path)
w = img.width
h = img.height
del(img)
txts = []
for data in json_data["shapes"]:
box = data["points"]
w1 = (box[0][0] + box[1][0]) / 2 / w
h1 = (box[0][1] + box[1][1]) / 2 / h
w2 = (box[1][0] - box[0][0]) / w
h2 = (box[1][1] - box[0][1]) / h
category_name = data["label"]
category_id = cat_id_dict[category_name]
txts.append(f"{category_id} {w1:.6f} {h1:.6f} {w2:.6f} {h2:.6f}")
# Output to YOLO txt Format
with open(txt_path, "w") as f_out:
for t in txts:
print(t, file=f_out)