
写真の良し悪しを数値化して判定するAIを作ってみたので、ざっくり記載する。
Ver.1は写真の点数を人が決める、Ver.2は2枚の写真の優劣だけを人が決める、という作り方による教師データを用いた。
Version 1
1.1 学習
学習するためのコード。ResNet50の最後をFC層+シグモイドに変えた。学習済みの重みをベースに、ファインチューニングした。
今回使ったoptimizerのSAMのコードは、以下のgithubよりお借りした(sam.pyを同フォルダに置く)。SAM+SGDは学習が遅いけど、その汎化性能はとても信頼している。
https://github.com/davda54/sam
import os
from glob import glob
from PIL import Image
from tqdm import tqdm
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader, random_split
from torchvision import transforms
from torchvision.models import resnet50, ResNet50_Weights
from sam import SAM
lr = 0.0005
momentum = 0.9
num_epochs = 50
batch_size = 64
early_stop = 10
model_name = "rn50_photo"
data_dir = "data_train"
log_dir = "torch_logs"
class MyDataset(Dataset):
def __init__(self, file_list):
self.file_list = file_list
self.transform = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])])
def __len__(self):
return len(self.file_list)
def __getitem__(self,index):
img_path = self.file_list[index]
img = Image.open(img_path).convert("RGB")
img_transformed = self.transform(img)
dirname = img_path.split("\\")[-2]
# 画像のフォルダ名が、0.0~1.0のレーティングの数値である前提
label = np.array([float(dirname)], dtype=np.float32)
return img_transformed, label
os.makedirs(log_dir, exist_ok=True)
model_filename = os.path.join(log_dir, model_name + ".pt")
log_filename = os.path.join(log_dir, model_name + ".csv")
# network
net = resnet50(weights=ResNet50_Weights.DEFAULT)
num_features = net.fc.in_features
net.fc = nn.Sequential(
nn.Linear(num_features, 1),
# 0~1の数値として回帰するためSigmoidを使用(なくても学習は可能)
nn.Sigmoid()
)
# 同名のファイルがあれば、それを初期値として読み込む(学習再開)
start_epoch = 0
continue_flag = 0
if os.path.isfile(model_filename):
net.load_state_dict(torch.load(model_filename))
continue_flag = 1
if continue_flag and os.path.isfile(log_filename):
with open(log_filename, mode="r") as f:
lines = f.readlines()
try:
start_epoch = int(lines[-1].split(",")[0]) + 1
except:
pass
else:
with open(log_filename, mode="w") as f:
print("epoch,t_loss,v_loss", file=f)
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"will use {device}")
net = net.to(device)
# 画像ファイルリスト
image_file_list = glob(data_dir + "/**/*.jpg", recursive=True)
image_file_list += glob(data_dir + "/**/*.jpeg", recursive=True)
image_file_list += glob(data_dir + "/**/*.png", recursive=True)
print(f"N = {len(image_file_list)}")
# 画像ファイルリストを分割->データセット->データローダー定義
train_ratio = 0.75
train_size = int(train_ratio * len(image_file_list))
val_size = len(image_file_list) - train_size
data_train, data_val = random_split(image_file_list,
[train_size, val_size])
train_dataset = MyDataset(file_list=data_train)
valid_dataset = MyDataset(file_list=data_val)
train_loader = DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True)
valid_loader = DataLoader(valid_dataset,
batch_size=batch_size,
shuffle=False)
### ロス関数と最適化手法(SAMを使用)の定義
criterion = nn.MSELoss()
optimizer = SAM(net.parameters(),
torch.optim.SGD, lr=lr, momentum=momentum)
no_imp = 0
least_loss = 100
# ループ
for epoch in range(start_epoch, num_epochs):
if epoch == start_epoch and continue_flag:
# 再開時、初回エポック時は学習しない
t_loss = 1.0
else:
# train
net.train()
running_loss = 0.0
total = 0
for images, labels in tqdm(train_loader):
if labels.size(0) == 1:
continue
images = images.to(device)
labels = labels.to(device)
# first forward-backward step
outputs = net(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.first_step(zero_grad=True)
running_loss += loss.item()
# second forward-backward step
outputs = net(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.second_step(zero_grad=True)
total += labels.size(0)
t_loss = running_loss / total
# valid
net.eval()
running_loss = 0.0
total = 0
with torch.no_grad():
for images, labels in tqdm(valid_loader):
if labels.size(0) == 1:
continue
images = images.to(device)
labels = labels.to(device)
outputs = net(images)
loss = criterion(outputs, labels)
running_loss += loss.item()
total += labels.size(0)
v_loss = running_loss / total
if v_loss < least_loss:
# v_lossが改善した場合のみ、重みを保存
least_loss = v_loss
torch.save(net.state_dict(), model_filename)
no_imp = 0
else:
no_imp += 1
# log
print(f"{epoch}\tt_loss:{t_loss:.6f} / v_loss:{v_loss:.6f}")
with open(log_filename, mode="a") as f:
print(f"{epoch},{t_loss},{v_loss}", file=f)
# early stop
if early_stop and no_imp > early_stop:
break
print("finished")よくある普通の画像認識AIの学習との主な違いは以下。
①画像のフォルダ名がレーティング(0.0~1.0)の数値
・フォルダ分けしているが、分類ではなく、この数値を回帰するAIとして学習する
・このためにResNetの最後をシグモイド(0.0~1.0に変換)にした
0.0はゴミ(部屋の中で単にシャッターを切っただけとか)、0.3は単に写っただけ(+αのない記念写真、または減点要素がある)、0.4は悪くはないけど良くもない写真(何らかの+αはある)、0.8はまずまずいいと思う写真(ブログ等に載せてもいいと思えるレベル)、1.0はかなりいいと思う写真を選んだ。
用意した画像の数は、0.0~0.8は各900±200枚くらい、1.0は100枚くらい。
0.4と0.8が写真的には大きな差がないにもかかわらず点数は大きく違うのは、その微妙な差を学習してほしいため。0.3以下はゴミ、0.8以上はいい写真だという判定でいいが、その中間のグラデーションをいい感じに判定してくれるといいなぁ、という思いがある。
今回はこのように分けたが、これがいいのかは分からない。

②縦画像も横画像も、正方形になるように黒画素(ゼロ)で拡張
・縦横画像とも、構図をそのまま評価してほしい
・学習用画像は事前に全部変換して保存しておく
・推論時はプログラム内でこの変換を行ってからAI判定する

③データ増強(学習用データの色相・彩度等のランダム変換、拡大や回転などのランダム変形)は行わない
・色も構図も、写真の良し悪しに関係しているから
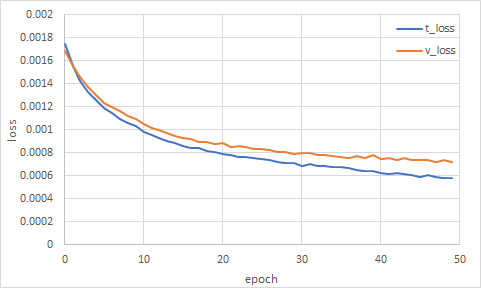
学習したところ、以下のように悪くない感じでロスが下がっていった。
1.2 推論
あるフォルダにある写真を採点して、点数をファイル名につけて、別のフォルダに出力(コピー)するコード。
import os
import shutil
from glob import glob
import cv2
from PIL import Image
import numpy as np
import torch
import torch.nn as nn
from torchvision import models, transforms
weights = "torch_logs/rn50_photo.pt"
test_dir = "test_data"
output_dir = "test_data/results"
os.makedirs(output_dir, exist_ok=True)
def imread(filename):
array = np.fromfile(filename, dtype=np.uint8)
img = cv2.imdecode(array, cv2.IMREAD_COLOR)
return img
transform = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])])
files = glob(os.path.join(test_dir, "*.jpg"))
net = models.resnet50()
num_features = net.fc.in_features
net.fc = nn.Sequential(
nn.Linear(num_features, 1),
nn.Sigmoid()
)
# 学習したモデルのロード
net.load_state_dict(torch.load(weights))
net.eval()
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"will use {device}")
net = net.to(device)
print("N =", len(files))
with torch.no_grad():
for filename in files:
# 前処理の前処理
img_cv = imread(filename)
w = img_cv.shape[0]
h = img_cv.shape[1]
if w > h:
img_new = np.zeros((w, w, 3), dtype=np.uint8)
a = (w - h) // 2
img_new[:, a:a+h, :] = img_cv
else:
img_new = np.zeros((h, h, 3), dtype=np.uint8)
a = (h - w) // 2
img_new[a:a+w, :, :] = img_cv
img = cv2.cvtColor(img_new, cv2.COLOR_BGR2RGB)
img = Image.fromarray(img)
del(img_cv)
# 前処理してAI判定
img_prep = transform(img)
img_prep = img_prep.unsqueeze_(0).to(device)
outputs = net(img_prep).cpu()
outputs = outputs.detach().numpy()
output = float(outputs[0])
# ファイル名に点数を付加してコピー
dirname, basename = os.path.split(filename)
basename2 = f"{output:.4f}_{basename}"
new_filename = os.path.join(output_dir, basename2)
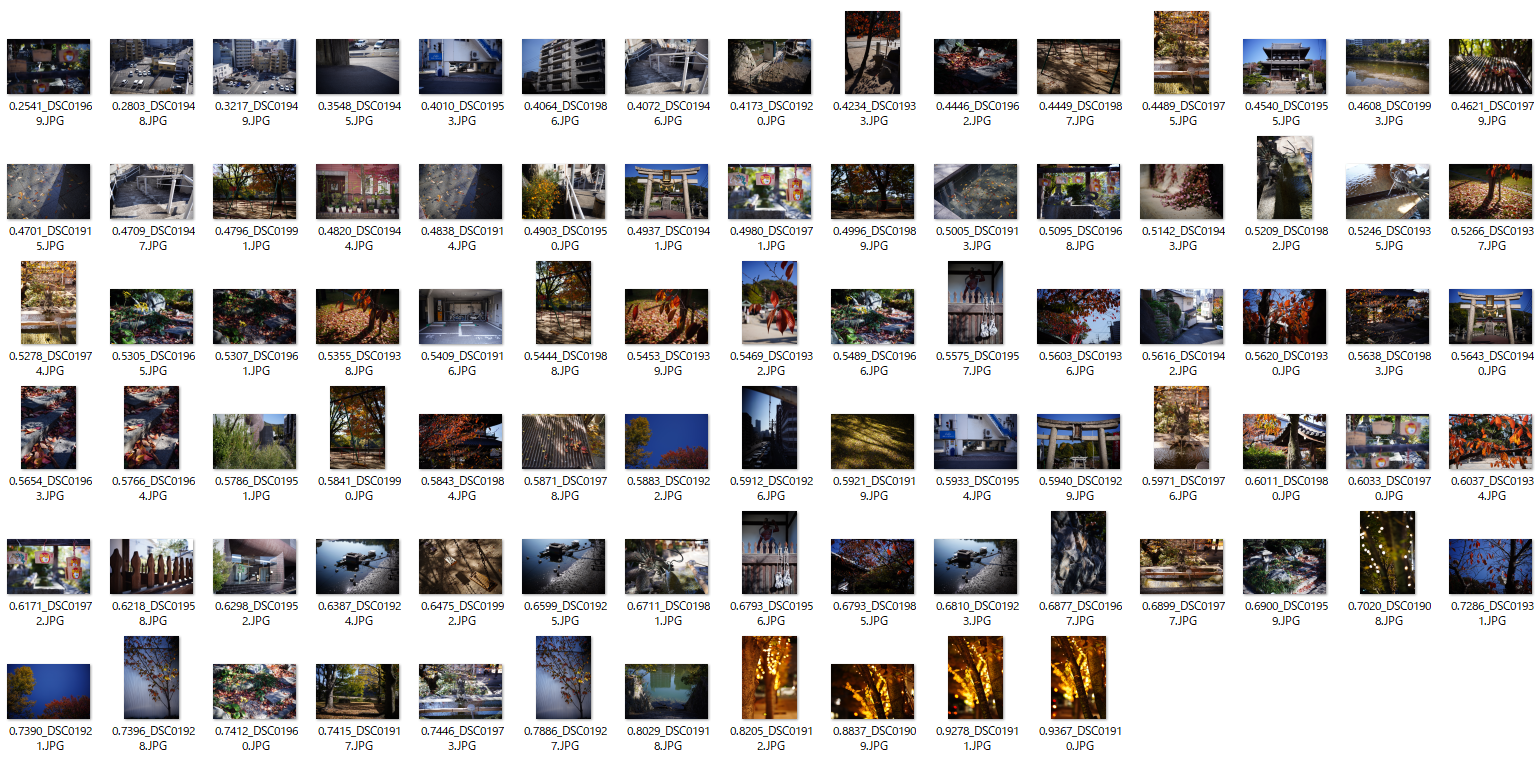
shutil.copy(filename, new_filename)学習には使っていない全86枚の写真を採点させてみた。各ファイル名の頭についている数字が点数。総合的には、1, 2列目の写真よりも3, 4列目の写真の方が、3, 4列目よりも4, 5列目の方が良い写真、のような気がする。
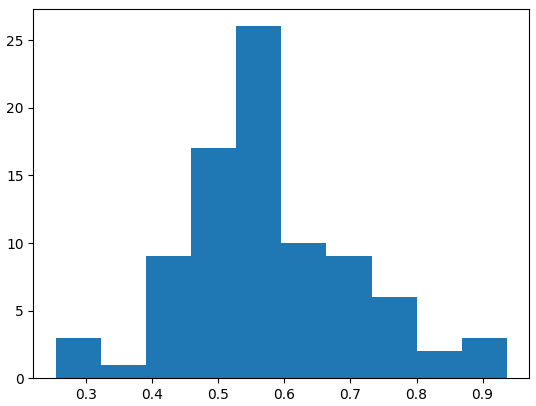
点数分布は以下のようになっていて、いい感じの分布のように見える。
ということで、最高得点0.93をたたき出した写真を掲載。良いとは思うけど、点数高すぎない?

戦闘力、たったの0.25か、ゴミめ。・・・いや、良くないのは認めるけど、そこまで酷い? ・・・まぁ、酷いか。

ほとんど同じ写真なのに点数が結構違う例。・・・このAIは周辺減光が好きなんかな? 開放バカなんかな?

ということで、目安程度には使えそうなAIを学習することができた。
1.3 再学習 (1/23追記)
学習データを見直し、再学習を行った。とりあえずこれで仮運用してみる。
2022年に撮った全写真の点数分布は以下の通り。個別のスコアが感覚的に正しいかどうかは別として、学習前に思い描いていたような分布がうまく作れた気がする。
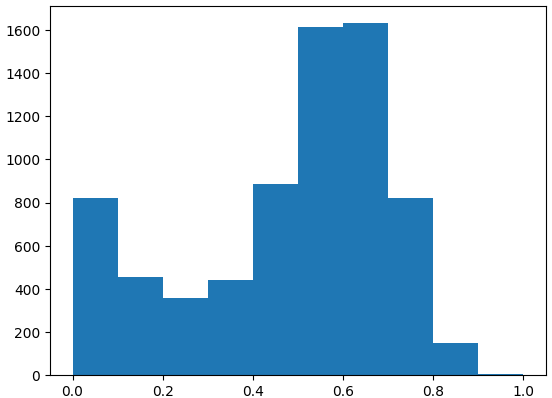
スコア0.3以下のゴミ写真率の高さにげんなりするが、まぁそうだろうなぁ。7000枚超のうち、スコア0.8以上は約150枚・・・まぁそうだろうなぁ。前掲のイルミネーションの写真は、偶然にも2022年のベストスコアらしい。
Version 2 (3/11追記)
やはり写真の得点を人間が絶対値で決めて、それを学習させるのは無理があると思った。なので、人間は2枚の写真を比べて、どちらの方が良いか(好きか)だけを決めて、それを学習させる、いわゆるランキング法のようなのをやってみたい。
2.1 ラベリング
ということで、まずはそのラベリングをするためのGUIを自作するところから。めんどくさいのでグローバル変数使いまくり。
import os
import random
from glob import glob
from PIL import Image, ImageTk
import tkinter as tk
import torch
import torch.nn as nn
from torchvision import models, transforms
in_dir = "1_data_train4"
save_path = "1_data_train4/_data.txt"
images = glob(os.path.join(in_dir, "**\*.jpg"), recursive=True)
transform = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])])
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"will use {device}")
# 学習したモデルのロード
weights = "torch_logs/rn50_photo8.pt"
if weights:
net = models.resnet50()
num_features = net.fc.in_features
net.fc = nn.Sequential(nn.Linear(num_features, 1), nn.Sigmoid())
net.load_state_dict(torch.load(weights))
print(f"load {weights}")
net.eval()
net = net.to(device)
else:
net = None
########################################
def good_left():
global img_path1, img_path2
save_txt(img_path1, img_path2)
view_images()
return
########################################
def good_right():
global img_path1, img_path2
save_txt(img_path2, img_path1)
view_images()
return
########################################
def inference(img_pil):
if net != None:
img_prep = transform(img_pil)
img_prep = img_prep.unsqueeze_(0).to(device)
outputs = net(img_prep).cpu()
outputs = outputs.detach().numpy()
output = float(outputs[0]) *100
return output
else:
return 0
########################################
def save_txt(img_path_b, img_path_w):
if save_path:
with open(save_path, "a") as f:
print(f"{img_path_b},{img_path_w}", file=f)
return
########################################
def view_images():
global img_path1, img_tk1
global img_path2, img_tk2
children = frame_main.winfo_children()
for child in children:
child.destroy()
frame1 = tk.Frame(frame_main, padx=5, pady=5)
frame1.grid(row=0, column=0, sticky=tk.W)
frame2 = tk.Frame(frame_main, padx=5, pady=5)
frame2.grid(row=0, column=1, sticky=tk.W)
frame3 = tk.Frame(frame_main, padx=5, pady=5)
frame3.grid(row=0, column=2, sticky=tk.W)
num = len(images)
img_path1 = images[random.randint(0, num-1)]
print(img_path1)
img_pil1 = Image.open(img_path1).convert("RGB")
point1 = inference(img_pil1)
img_tk1 = ImageTk.PhotoImage(img_pil1)
b1 = tk.Button(frame1, compound="top", command=good_left)
b1.configure(image = img_tk1)
b1.pack()
tk.Label(frame1, text=f"{point1:.1f}").pack()
img_path2 = images[random.randint(0, num-1)]
print(img_path2)
img_pil2 = Image.open(img_path2).convert("RGB")
point2 = inference(img_pil2)
img_tk2 = ImageTk.PhotoImage(img_pil2)
b2 = tk.Button(frame2, compound="top", command=good_right)
b2.configure(image = img_tk2)
b2.pack()
tk.Label(frame2, text=f"{point2:.1f}").pack()
tk.Button(frame3, text="SKIP", command=view_images).pack()
return
########################################
if __name__ == "__main__":
root = tk.Tk()
root.title("Select Better Photo")
root.geometry("550x270")
frame_main = tk.Frame(root, padx=5, pady=2)
frame_main.grid(row=5, column=0, sticky=tk.W)
view_images()
root.mainloop()
読み込む画像は事前に正方形になるように、黒ピクセルで埋めてある前提。写真の下には参考として前回学習済みのAIによる得点を表示している。
悩んでも仕方ないので、さくさく選んで、私の好みをAIに教え込んでいく。選んだ方と選ばなかった方のファイルパスをカンマで連結した文字列が、指定したテキストファイルに追記されていく。基本的にスキップしていいのは、2枚とも同じ写真が出てきた時だけ。
2.2 学習
import os
from PIL import Image
from tqdm import tqdm
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader, random_split
from torchvision import transforms
from torchvision.models import resnet50, ResNet50_Weights
from sam import SAM
lr = 0.0001
momentum = 0.9
num_epochs = 5
batch_size = 32
early_stop = 10
model_name = "rn50_photo11"
log_dir = "torch_logs"
txt = "1_data_train4/__data.txt"
with open(txt, "r") as f:
dataset = [line.strip().split(",") for line in f.readlines()]
####
class MyDataset(Dataset):
def __init__(self, file_list):
self.file_list = file_list
self.transform = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
def __len__(self):
return len(self.file_list)
def __getitem__(self,index):
img_path1, img_path2 = self.file_list[index]
img1 = Image.open(img_path1).convert("RGB")
img_transformed1 = self.transform(img1)
img2 = Image.open(img_path2).convert("RGB")
img_transformed2 = self.transform(img2)
return img_transformed1, img_transformed2
os.makedirs(log_dir, exist_ok=True)
model_filename = os.path.join(log_dir, model_name + ".pt")
log_filename = os.path.join(log_dir, model_name + ".csv")
# network
net = resnet50(weights=ResNet50_Weights.DEFAULT)
num_features = net.fc.in_features
net.fc = nn.Sequential(nn.Linear(num_features, 1), nn.Sigmoid())
# 同名のファイルがあれば、それを初期値として読み込む(学習再開)
start_epoch = 0
continue_flag = 0
if os.path.isfile(model_filename):
net.load_state_dict(torch.load(model_filename))
continue_flag = 1
if continue_flag and os.path.isfile(log_filename):
with open(log_filename, mode="r") as f:
lines = f.readlines()
try:
start_epoch = int(lines[-1].split(",")[0]) + 1
except:
pass
else:
with open(log_filename, mode="w") as f:
print("epoch,t_loss,v_loss", file=f)
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"will use {device}")
net = net.to(device)
# 画像ファイルリスト
print(f"N = {len(dataset)}")
# 画像ファイルリストを分割->データセット->データローダー定義
train_ratio = 0.75
t_size = int(train_ratio * len(dataset))
v_size = len(dataset) - t_size
data_train, data_val = random_split(dataset, [t_size, v_size])
train_dataset = MyDataset(file_list=data_train)
valid_dataset = MyDataset(file_list=data_val)
train_loader = DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True)
valid_loader = DataLoader(valid_dataset,
batch_size=batch_size,
shuffle=False)
def criterion(outputs1, outputs2):
diff = outputs2 - outputs1
diff = nn.functional.leaky_relu(diff, negative_slope=0.2)
diff = diff.mean()
return diff
optimizer = SAM(net.parameters(),
torch.optim.SGD, lr=lr, momentum=momentum)
no_imp = 0
least_loss = 100
# ループ
for epoch in range(start_epoch, num_epochs):
if epoch == start_epoch and continue_flag:
# 再開時、初回エポック時は学習しない
t_loss = 1.0
else:
# train
net.train()
running_loss = 0.0
total = 0
for images1, images2 in tqdm(train_loader):
if images1.size(0) == 1:
continue
images1 = images1.to(device)
images2 = images2.to(device)
# first forward-backward step
outputs1 = net(images1)
outputs2 = net(images2)
loss = criterion(outputs1, outputs2)
loss.backward()
optimizer.first_step(zero_grad=True)
running_loss += loss.item()
# second forward-backward step
outputs1 = net(images1)
outputs2 = net(images2)
loss = criterion(outputs1, outputs2)
loss.backward()
optimizer.second_step(zero_grad=True)
total += images1.size(0)
t_loss = running_loss / total
# valid
net.eval()
running_loss = 0.0
total = 0
with torch.no_grad():
for images1, images2 in tqdm(valid_loader):
if images1.size(0) == 1:
continue
images1 = images1.to(device)
images2 = images2.to(device)
outputs1 = net(images1)
outputs2 = net(images2)
loss = criterion(outputs1, outputs2)
running_loss += loss.item()
total += images1.size(0)
v_loss = running_loss / total
if v_loss < least_loss:
# v_lossが改善した場合のみ、重みを保存
least_loss = v_loss
torch.save(net.state_dict(), model_filename)
no_imp = 0
imp_mark = "*"
else:
no_imp += 1
imp_mark = ""
# log
print(f"{epoch}/{num_epochs-1}\tt_loss:{t_loss:.6f} / v_loss:{v_loss:.6f}{imp_mark}")
with open(log_filename, mode="a") as f:
print(f"{epoch},{t_loss},{v_loss}", file=f)
# early stop
if early_stop and no_imp > early_stop:
break
print("finished")前回との違いは、データセットクラスが上記2枚の画像(を前処理したもの)を返すようになっていて、各エポックではそれぞれNNが採点した2枚の画像の得点の差(worse ー better)のLeakyReLU(正解なら小さな報酬、不正解なら大きなペナルティ)を取り、そのバッチ平均を損失関数として、これを最小化(負の値を最大化)するように学習を進める。
NNアーキテクチャー自体は、前回と完全に同じものを使っている。重みも前回学習済みのものをベースに学習再開している。同時に2枚の画像のAI判定を行うため、使用メモリは2倍になるので、バッチサイズは小さくせざるを得ない。
2.3 推論
推論は前回と100%一緒なのでコードは省略。
2.4 検証
ということで、1月末ごろにはコードは一通り準備はできたんだけど、学習データを作るところ(ラベリング)が大変である。写真は適当に3500枚くらいで、気が向いたときにちまちまラベリングしていて、現状4000セットくらいデータを作った。この10倍くらい欲しい気がするが、いったんこれで学習してみた。
検証の準備としては、学習に利用しなかった写真15枚について、2枚を抽出してその良し悪しを主観判定する、という作業を総当たりで行った。この勝率順位をManual rankとする。
次に、前回の方法で学習したv8と、今回の手法で学習したv11(v8を初期値としてファインチューニング)で採点し、それぞれの順位(Rank by AIとする)を、前述のManual rankと比較した。以下にその結果を示す。
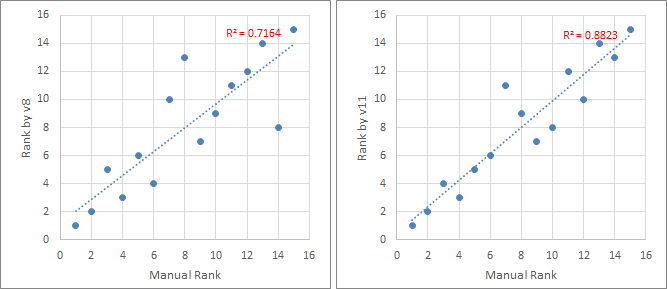
・・・データが少ないわりに、なかなか悪くないんじゃなかろうか? 検証データも少ないので雑なものだが、まぁ、私の好みをある程度教え込むことができた、ということで、いったん終了。